
I decided to start a series of post related to SAP HANA Best Practices. The idea popped up in my mind a few weeks ago when I was checking a SAP HANA databases from several of my customers. It seems that there are some basic best practices that nobody follows… Maybe because they are not known by most of the SAP Basis Admins or because people is lazy, who knows.
The main idea with this post series is to give you a list of best practices and recommendations that you can follow so you will avoid issues and problems in the future. Most of them are really easy to follow and it won’t take you a lot of time. Let’s start!
Archiving and deleting data
If you are reading this you probably know that SAP HANA stores data on a persistence layer (data and logs). When you start your database the data is loaded into the physical memory. Not all the data is loaded into the memory at this moment. Only those tables that have the PRELOAD flag enabled will be loaded into the memory. It is also possible to enable the PRELOAD flag just for some columns of the table.
The SAP HANA database will load tables and columns into memory when those are required. This could happen because explicit access, explicit load, index load/recreation after optimize compression, etc. For example, if I execute a SELECT * FROM TABLE and I have enough memory that table will be fully load into memory in case it wasn’t. If it is a huge table (like tens or hundred of GB) then OOM situations could appear.
On the contrary, HANA unloads tables from memory on certain situations. For example, when the SAP HANA database runs low on memory, on MERGE/SHRINK situations or when the UNLOAD of the table was explicit. A high number of loads/unloads could affect the performance of the system since the database have to bring the table/columns before the process using it can access it. You can read a lot about LOAD/UNLOAD operations in SAP HANA in the SAP Note 2127458 – FAQ: SAP HANA Loads and Unloads.
Now that I explained a bit about memory and LOAD/UNLOAD operations in SAP HANA I want to give you the following example. Let’s say that your SAP HANA database have 1TB physical memory available. Your biggest table is EDID4 table which is a cluster table related to IDoc logging. The table’s size is 100GB. A couple of months later the EDID4 table increased its size to 250GB. That will mean that process on your SAP using this table will now use a table that doubles the size.
Remember, in SAP HANA the size of a table usually means a memory requirement so the database can load the table in memory. If the table doubles its size on the persistent layer that will mean that if we want to load that table in the physical memory we will need the double amount of memory. This is not 100% accurate but it helps to describe my idea:
Size of a table = Space on the persistent layer = Physical memory = Money
If we don’t archive or delete data from our database sooner or later we will run out of memory. When HANA runs of memory when OOM situations start to appear and people scream because process are being cancelled. Also, if we run Calculation Views on the SAP HANA database (for example from a BW Load Chain) the number of rows managed by the calculations views will increase. This means that the calculation view will take more memory to be processed, more time to finish, etc.
[adinserter block=”7″]
Archiving is an operation that has been around since the beginning of times. It basically means that we take part of the data from our database and we moved it to a different storage reducing the database size. We can choose the data to be moved depending on certain factors. It is also possible to delete the data in case it doesn’t have any value for us. There are multiple ways to archive data, usually we can do it using the SARA transaction.
To be honest, there are other ways to reduce the memory used by a SAP HANA database. Today I want to focus on archiving and deleting data since they are two of the easiest way to reduce the memory consumption. The next step is to know which tables we can reduce and how to do it. First, about knowing the tables we can use the following options:
- Perform a DVM (Data Volume Management) Analysis Report on a Solution Manager 7.2 for the SAP HANA Database and the SAP system using the database. Basically the Solution Manager will connect to the database, check the biggest tables and provide some recommendations that we can follow to reduce its size. The DVM configuration is super easy, just follow the wizard on the Solution Manager.
- Check the biggest tables in the SAP HANA Database and find notes and procedures to archive/delete data. We can do it on different ways:
- Using transaction DB02 and the option System Information – Large Tables. Order by Estimated max Memory Size in Total.
- Using the SAP HANA Mini Checks in the SAP HANA Studio.
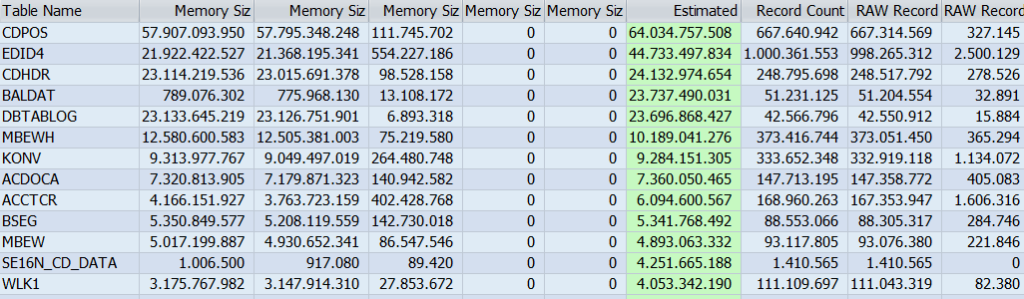
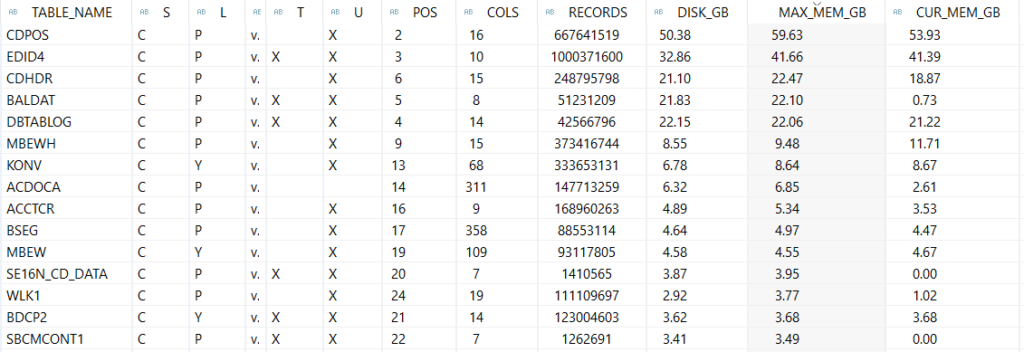
- Using a third-party tool as SNP or similar.
Once we know the tables the next step is to know how to reduce the size of those tables:
- For archiving data from the tables you can use transaction SARA, SAP DVM or a third-party tool. I won’t give details now about this operation since the archiving topic requires a really long explanation.
- For deleting data from the tables we can follow the SAP Note 2388483 – How-To: Data Management for Technical Tables. This note describes each of the technical tables, its area and the reports/programs/methods to delete or even archive the data.
Both archiving and deleting data are critical operations on a SAP HANA database. Reduce the tables size means that we will reduce the physical memory required for loading that table and also the memory required by different operations using that table.
Consistency Check
There are different types of consistency when talking about database. It could be related to data consistency, transaction consistency, etc. In this case I want to talk about data consistency. For HANA database consistency means the lack of data corruption within the database. The data corruption could be related to a logical corruption within SAP HANA (for example a bug) or to a page corruption on disk level (for example, layers below SAP HANA as disk controller, operating system, etc).
Data corruption could be not detected immediately right after it happen, it could take days, months or even years. Let’s say that you SAP HANA database performs a delta merge on a table from memory to disk and on that specific moment the disk related to the persistent storage fails and part of the data is not written into the disk. Later, you try to perform a LOAD of the table into memory and SAP HANA cannot read the bits since it cannot access to that specific block. There are tons of different reasons why corruption can appear on a database. I seen cases of corruption on Oracle, ASE, DB2 and even SAP HANA that caused a incredible high amount of financial loss on a company. The worst case I remember was on an IBEX35 company that lost 4 days of production work on their SAP ERP because a malfunctioning disk. When they detected the problem it was too late. Data corruption is one of the scariest scenarios you can have. It’s a pain in the
[adinserter block=”7″]
There are tons of different options to avoid or fix situations like this. For example, following a strict backup policy can minimize the impact of data corruption. Disaster recovery plans can be created so in case of data corruption the disruption on the business will be as low as possible. Data consistency check can be performed so data corruption will be detected as soon as possible. I can talk for days about these options but now I want to focus on data consistency check.

In SAP HANA there are multiple options to perform a consistency check depending on the level we want to check. I already talked about it my the latest post about upgrading to SAP HANA 2.0. The SAP Note 1977584 – Technical Consistency Checks for SAP HANA Databases describes the possible options. The basic consistency check you should perform is:
- Use CHECK_CATALOG to check the SAP HANA metadata consistency.
- Use CHECK_TABLE_CONSISTENCY for checking tables consistency in column store and row store.
- Use uniqueChecker.py for checking consistency for tables in column store.
These checks should be performed within the backup retention time so in case we need to restore the database we could do it. Also the consistency check use a high amount of resources (specially CPU) so it is better to do it out of business hours or peak workload. You can do it using the following options:
- Use transaction DB13 to schedule a job for the action CHECK_TABLE_CONSISTENCY.
- Use the embedded statistics server on the SAP HANA database.
- Use a cron on the Operating System to execute the scripts you prepare.
Depending on the output of the consistency checks the actions to be perform are different. It also depends on the type of error, affected table, etc. I strongly recommend reading the following SAP Note because it have tons of information about data corruption and consistency check in SAP HANA: 2116157 – FAQ: SAP HANA Consistency Checks and Corruptions