
One of the problems that I usual find on SAP Systems running with DB2 is the performance of the full backup. Unfortunately this is one of the topics that is most difficult to find information about. Of course we can find information about the backup buffer size, parallelism, backup devices performance, etc. But sometimes the issue cannot be solved changing the backup parameters or improving the backup device.
The last two cases I found were on systems where the full backup took between 12 – 15 hours. After a while I found a way to solve it which it is an interesting project that you can do in your SAP Systems running on DB2.
The problem
The full backup on a SAP System running on DB2 took between 12 to 15 hours to finish. This same issue happens on DB2 running on either 10.5 and 11.1 version. The full backup was performed using DBACOCKPIT on the SAP System so no TSM was involved in the backup operation. The first thing we tried was changing the backup device from a device mounted via NFS in the OS to a local disk in the server. Unfortunately the backup operation improved just a couple hours still taking a long time.
The same issue was found with different SAP Products and versions running on a DB2 database.
The investigation
The first step is to recover some information about the backup. The following SAP Notes will help you:
- 1171143 – DB6: Collecting data for backup performance issues
- 2038748 – DB6: Data collection for database online backup performance issues
Check also the db2diag.log file in the /db2/SID/db2dump directory since it contains information about the backup performance. The results will be something like this:
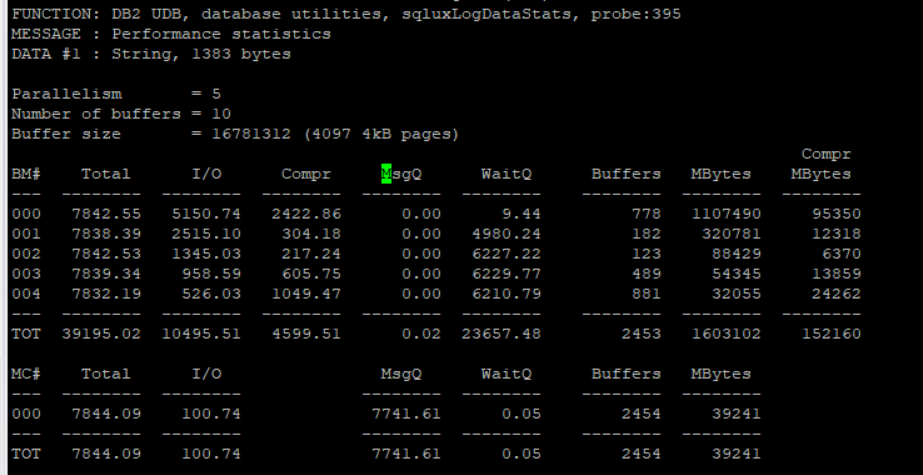
As you can see in the screenshot in this case we executed the backup with 5 threads for parallelism and a buffer size of 4097 4kB pages. For each of the executed threads you can see the total time, the data transferred, etc. I recommend checking the following information about the recommended values for parallelism and buffer size:
- DB2 – Optimizing backup performance
- 141872 – Specifying the buffer size for backup
- IBM Redbooks – Maximizing Performance of IBM DB2 Backups
There are also multiple articles in Internet about how to understand the backup statistics and which actions take considering the statistics. Right now the most important thing is to understand how parallelism works on a DB2 Backup. Each of the threads configured in the backup operation will take care of one tablespaces each time. You can see it on real time if you check the tablespaces status on transaction DB2. While the backup is being executed the tablespaces status will show the backup operation ongoing. When the thread finish backing up the tablespace it will backup a new tablespace and release the old tablespace, changhing the status in the DB2 transaction. This is important because sometimes it doesn’t matter the value of the parallelism value.
[adinserter block=”7″]
If one of the tablespaces is bigger compared with the rest of tablespaces then the parallelism value doesn’t matter. When a thread finish backing up one tablespace it will jump to the next tablespace available for backup. If there are no tablespaces left then the backup operation will wait until the last tablespace finished backing up. So it doesn’t really matter the number of parallel process configured if the backup operation has to wait for a huge tablespace.
You can understand the problem easier checking the following screenshot:
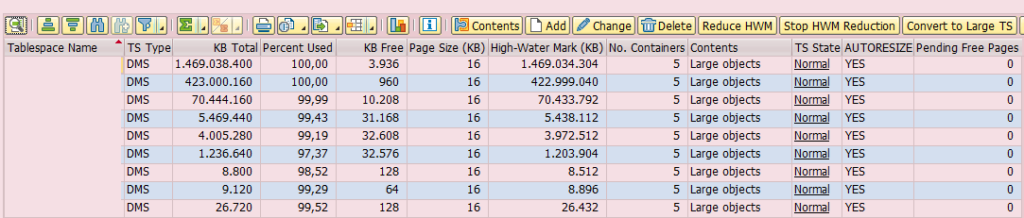
As you can see there is one tablespace of 1,4TB within the database. The backup operation will finish with the rest of tablespaces really soon and then it will have to wait for the biggest tablespace to finish. Unfortunately this is an issue I found of several SAP systems. When installing SAP the installation process creates X tablespaces with the name SID#BTABD, SID#BTABI, SID#DDICD, SID#DDICI, etc. The ones finishing on D are data tablespaces while the ones finishing on I are index tablespaces. Personally I don’t know how it distributes the tables on each tablespace. I found tablespaces with really heavy tables as FLAGFLEXA, VBFA, VBAP, BSIS, etc. in the same tablespace.
In the end it doesn’t matter the buffer and parallelism settings, the backup device performance, etc. if your data is distributed unevenly in the tablespaces.
The solution
We have several possibilities to fix this performance problems, it depends on what you prefer.
The first possibility would be to create new tablespaces and move the biggest tables into this new tablespaces. The new tablespaces will have names as SID#BTABD_1, SID#BTABI_1, SID#BTABD_2, etc. After that we will use the program DB6CONV to move the biggest tables to this new tablespaces. So if the FLAGFLEXA table is on tablespace SID#BTABD and SID#BTABI we will move it to the tablespaces SID#BTABD_1 and SID#BTABI_1.
The second option and in my opinion more sophisticated is to created a tablespace pool using the procedure described in the SAP Note
2267446 – DB6: Support of tablespace pools. This way we will create a new tablespace wpool with the name SID#NAME@NUMBERD/I/L. For the data tablespaces will be something like SID#DATA@1D and for the index tablespace it will be something like SID#DATA@1I. The number of tablespaces to be created will be define when creating the tablespace pool in DBACOCKPIT transaction as an automatic storage tablespace. You can use the following reports for simulating the new tablespace organization:
- RSDB6TBSPOOLMAP: Simulates the tablespace assignment in the tablespace pool for a single table.
- RSDB6TBSPOOLDISTRIB: Simulates the table distribution over the various tablespaces in a tablespace pool.
- RSDB6TBSPOOLTABART: Changes the SAP standard data classes to the new tablespace pool. Important if you delete the old tablespaces in the future.
I will create a new entry explaining how to use DB6CONV and giving you some tips and tricks while working with it.
Our goal is to distribute the biggest tables on a tablespace pool so we will reduce the time a single thread takes in order to backup the tablespace where the table is stored. If we reduce the time the threads takes to finish the backup operation we will reduce the overall database backup. The idea is to reduce and redistribute the tablespace as much a possible.
In our case the tablespaces were distributed in the following way:
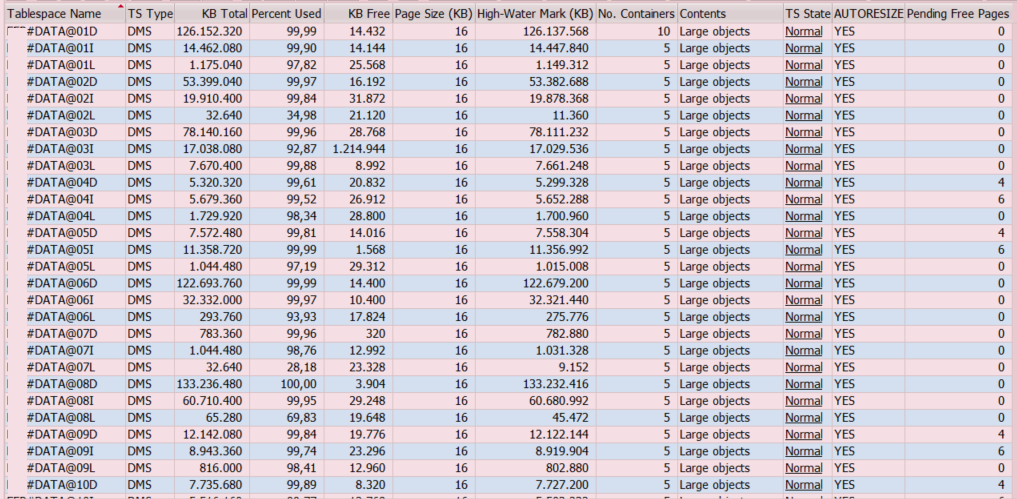
The biggest tablespace size before distributing the tables in the new tablespace pool was 1,2TB. After the distribution our biggest tablespace within the database is 196GB.
Conclusions
We managed to reduce the backup time from 12-15 hours to 4 hours after reorganizing the database and moving tables to a new tablespace pool with evenly sizes. It is a huge improvement that it’s worth the work. It took about 2 months moving tables within the database and a lot of pain but I couldn’t be happier with the results.
As a recommendation: Not always performance issues are related to a bad configuration of the system, the database or appliances used in the SAP system. Sometimes they are related to how the data is managed and storage within the database so its important to keep an eye on all the possible levels.
DB2 Tablespace Pools are not new. Actually there are been around for a while and newer SAP installation has the option available for using tablespace pools instead of traditional tablespaces. If you are going to install a new SAP System running on DB2 consider using tablespace pools in order to avoid problems in the future. If you are running SAP Systems with DB2 consider moving the data to a new tablespace pool. This will avoid DB2 Backup Performance in the future!